






L’approche “API first”, est une stratégie de développement d’applications dans laquelle la conception et le développement des API ont la priorité sur les autres composants logiciels, les plaçant au premier plan du processus de développement dès le début. Avec l’API d’abord, chaque API est traité en tant que produit individuel, qui permet aux développeurs de créer des systèmes plus évolutifs, maintenables et interopérables. Elle est du coup associée à une approche top-down via Open API et les générateurs automatiques des implémentations.
Solution permettant la surveillance, la gestion de la performance, la disponibilité des applications logicielles. Elle permet de diagnostiquer rapidement (intégration avec le code) la source d’erreur. Ex : Sentry
Selon l’état du “Health check”, cette stratégie permet de recréer la VM pour avoir une continuité de service au sein d’un MIG.
Descripteur en JSON et sérialisation en binaire compact.
Protocole d’échange de route externe, utilisé notamment sur le réseau Internet. Son objectif principal est d’échanger des informations de routage et d’accessibilité de réseaux entre Autonomous Systems (AS).
Pratique qui consiste à utiliser ses équipements personnels dans un contexte professionnel. Cette pratique pose des questions relatives à la sécurité de l’information et à la protection des données, ainsi que sociales et juridiques.
Prévoir les différentes montées en charge à mettre en place, et anticiper l’usage intensif d’un service.
Dépenses qui ont de la valeur sur le long terme.
Pattern permettant de suivre les modifications de la donnée et d’y associer des actions (ex : synchronisation, etc).
Détecter les problèmes rapidement, mettre en place des procédures de ‘rollback’ et automatiser au maximum les procédures.
Proxy devant le service le protégeant contre l’engorgement (“cascading failure; open, half open, close modes”). Une stratégie de retry, fallback, bulck head ou timeout peut être ajouté pour gérer la résilience. Avec ces deux modèles, une continuité de service peut être assurée.
Une IP (ou un masque) est composé de 32 bits :
255.255.255.255 255 décimal -> 1 octet -> 8bits -> 11111111.11111111.11111111.11111111
CIDR= (IP ou masque)/(nombre de bit 1 réservé)
ex : 10.0.0.0/20 (20 bits réservés) => 255.255.240.0
10.0.0.0/16 => 255.255.0.0 => 10.0.1.16 et 10.0.150.1 sont dans le même sous réseau.
Moins de bit réservé pour identifier le réseau => plus grand est la plage IP disponible pour les hôtes.
Ex: 10.0.0.0/16 -> 255.255.0.0 (16 =2 octets) -> 2^(32-13) - 4 =65536-4 =65532 IP réservables pour les hôtes. 10.1.0.0/10 -> 0.63(1100 0000 -> 2⁶-1).255.255 -> [10.0.0.0,10.63.255.255].
‘4’ car deux adresses sont toujours réservées dans chaque réseau : l’adresse réseau (seulement 0s dans la partie hôte), qui sert à identifier le réseau et l’adresse de diffusion (uniquement 1s dans la partie hôte), qui est utilisée pour la transmission à tous les participants au réseau.
| RFC 1918 name | IP address range | Number of addresses | Largest CIDR block (subnet mask) | Host ID size | Mask bits | Classful description[Note 1] |
|---|---|---|---|---|---|---|
| 24-bit block | 10000 – 10255255255 | 16777216 | 10000/8 (255000) | 24 bits | 8 bits | single class A network |
| 20-bit block | 1721600 – 17231255255 | 1048576 | 1721600/12 (25524000) | 20 bits | 12 bits | 16 contiguous class B networks |
| 16-bit block | 19216800 – 192168255255 | 65536 | 19216800/16 (25525500) | 16 bits | 16 bits | 256 contiguous class C networks |
Plateforme de développement pour les applications mobiles souvent associée à Firestore.
L’architecture composable est une approche modulaire de la conception et du développement de logiciels qui permet de créer une architecture logicielle flexible, réutilisable et adaptable. Elle consiste à décomposer des plateformes monolithiques étendues en composants petits, spécialisés, réutilisables et indépendants. Ce modèle architectural comprend un ensemble de composants modulaires enfichables, tels que des microservices, des capacités métier packagées (PBC) ,une architecture headless et un développement API-first qui peuvent être remplacés, assemblés et configurés de manière transparente pour s’adapter aux exigences de l’entreprise.
Un système de conception composable est une approche de microservices pour le développement de logiciels qui permet de combiner et de reconfigurer des composants individuels pour répondre à des exigences spécifiques dans le développement de systèmes. Les architectures composables englobent souvent une gamme plus large de composants et de services potentiellement plus importants que les architectures de microservices. D’autre part, les microservices peuvent être utilisés avec des API pour créer des technologies composables. De cette façon, les microservices peuvent être une implémentation spécifique d’architectures composables. Les microservices se concentrent le plus souvent sur des capacités métiers de petite taille et spécifiques, tandis que les architectures composables sont plus larges.
Capacité à récupérer après une interruption brutale sans perdre ni corrompre les données qui étaient déjà enregistrées sur un disque persistant avant le crash.
Parcours utilisateur les plus importants.
En programmation événementielle, la succession entraîne le multiple rejeu d’une même action. Le mécanisme anti-rebond permet d’éliminer ce rejeu en traitant que le dernier événement. Ce processus permet d’améliorer les performances du système et l’expérience utilisateur.
Déclaratif définit l’état final souhaité pour le système. La mécanique de mise à jour va alors exécuter les actions pour atteindre cet état. Impératif définit l’action à exécuter. La mécanique de mise à jour va appliquer cette action sans garantie de l’état final. .
Le principe de défense en profondeur revient à sécuriser chaque sous-ensemble du système, et s’oppose à la vision d’une sécurisation du système uniquement en périphérie. Chaque composant effectue lui-même toutes les validations nécessaires pour garantir la sécurité.
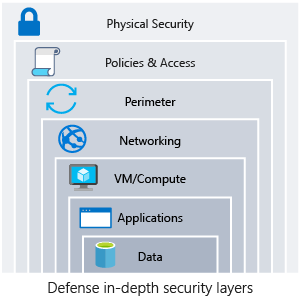
Action perturbatrice à prendre en compte lors d’une intervention sur l’infra.
Mécanisme de sécurité signant les transactions DNS et assurant l’intégrité et la provenance du message (évite-le “poisining”). Avec les DNSSEC, les requêtes DNS et les réponses ne sont pas elles-mêmes signées, ce sont les données DNS qui sont signées par le propriétaire des données.
Définir rapidement une réponse à l’incident.
Le “last-mile security” est le fait de protéger le service backend mis en proxy par le service d’API Gateway (par exemple). Le but étant d’empêcher qu’un attaquant puisse accéder directement aux services du backend en contournant le proxy (API Gateway). Il peut être mis en place une authentification mutuelle (TLS client/serveur) voir service mesh, clé d’API, OAuth, SAML, …
consiste à calculer le taux d’indisponibilité que nous pouvons tolérer pour un système. Il s’agit donc de définir le taux de disponibilité maximale que nous voulons atteindre et de se servir de l’écart entre le taux de disponibilité souhaité et le taux de disponibilité maximale (100%) pour innover ou améliorer un produit. Monitorer l’indisponibilité.
Processeur automatisé de transformation de données.
L’échec accéléré, ou fail fast, est une philosophie qui valorise les tests étendus et le développement incrémental, afin de déterminer si une idée présente ou non une valeur. Cette philosophie a pour principal objectif de diminuer les pertes lorsque des tests révèlent un dysfonctionnement, et de rapidement tenter autre chose : concept connu sous le nom de « pivotement » (pivoting).
Protocole concurrent à REST orienté performance (UC: microservice, haute performance, non UC: API publique car prise en charge limité par les navigateurs, non lisible par l’être humain: payload en binaire).
| Fonctionnalité | gRPC | API HTTP avec JSON |
|---|---|---|
| Contrat | Obligatoire (proto) | Facultatif (OpenAPI) |
| Protocol | HTTP/2 | HTTP |
| Payload | Protobuf (petit, binaire) | JSON (grande, lisible par l’homme) |
| Prescriptiveness | Spécification stricte | Lâche Tout HTTP est valide |
| Diffusion en continu | Client, serveur, bidirectionnel | Client, serveur |
| Prise en charge des navigateurs | Non (nécessite grpc-web) | Oui |
| Sécurité | Transport (TLS) | Transport (TLS) |
| Génération de code client | Oui | Outils OpenAPI + tiers |
Processus définissant les règles et les stratégies de gestion des ressources et des applications. Elle permet de gérer plus facilement le respect de la mise en conformité (ex : PCI-DSS).
Disciplines de gouvernance communes qui contribuent à éclairer les stratégies et à aligner les chaînes d’outils. Ces disciplines orientent les décisions en matière de niveau d’automatisation et de mise en œuvre de la stratégie d’entreprise entre plateformes cloud.
Le système est résilient à la panne en fournissant un système dégradé qui fonctionne quand même. Ex : Service des virements HS -> portail de la banque fonctionne, mais l’onglet virement a disparu.
Système dont la disponibilité est très élevée (arrêt du service extrêmement rare). La résilience est un élément permettant le HA.
Application dont les fonctionnalités sont développées sans interface utilisateur. Le service backend est accessible via une API et le frontend est un client de l’API
Désigne les activités de calculs réalisés sur un supercalculateur, en particulier à des fins de simulation numérique et de pré-apprentissage d’intelligences artificielles.
Architecture avec un point de connexion central. Ex : gestion des logs centralisés
On profite de la migration pour optimiser la solution au cloud.
Vitesse de lecture écriture par seconde.
Test qui valide l’interaction de différentes parties du code.
Protocole informatique utilisé pour mettre en place les informations de sécurité partagées dans IPSec.
Ensemble des protocoles utilisant des algorithmes permettant le transport sécurisé sur un réseau IP. (utilisé pour les VPN)
Mécanisme destiné à repérer des activités anormales ou suspectes sur la cible analysée. Il permet d’avoir une connaissance sur les tentatives réussies comme échouées d’intrusions.
Ex : Cloud IDS (GCP avec PaloAlto) + packet mirroring
voir SIEM et packet mirroring
Protocole réseau sans connexion de la couche 3 du modèle OSI. Grâce à des adresses de 128 bits (16 octets) au lieu de 32 bits (4 octets), IPv6 dispose d’un espace d’adressage bien plus important qu’IPv4
Le NAT n’est plus nécessaire.
128 bits => 8 groupes de 16 bits => 1 charactère 4 bits ex d’équivalence: 2001:0db8:0000:85a3:0000:0000:ac1f:8001 2001:db8:0:85a3::ac1f:8001
| Préfixe IPv6 | Description | Terme anglais | Détail | Équivalent IPv4 |
|---|---|---|---|---|
| ::1/128 | Boucle Locale | Node-local | ||
| Loopback | Adresse de bouclage, utilisée lorsqu’un hôte se parle à lui-même (ex : envoi de données entre 2 programmes sur cet hôte). | 127.0.0.0/8 (principalement 127.0.0.1)[28] | ||
| fe80::/10 | Liaison Locale | Link-Local | Envoi individuel sur liaison locale (RFC 4291[29]). Obligatoire et indispensable au bon fonctionnement du protocole. | 169.254.0.0/16 |
| 2000::/3 | Monodiffusion Mondiale | Global Unicast | Plage d’adresse publique, routable sur Internet, globalement uniques (doublon impossible) - Hors exceptions mentionnées ci-dessous. | |
| fc00::/7 | Localement Unique | Unique Local | Plage d’adresse privée, réservée à l’utilisation sur les réseaux locaux domestiques et d’entreprises. Elles ne sont pas globalement uniques (doublon possible, réutilisées sur plusieurs réseaux IP privés). | 10.0.0.0/8 |
| 172.16.0.0/12 | ||||
| 192.168.0.0/16 | ||||
| ff00::/8 | Multidiffusion | Multicast | Diffusion groupée (RFC 4291[29]) | 224.0.0.0/4 |
| 2001:db8::/32 | Documentation | Documentation | Plage réservée pour utilisation comme valeurs d’exemple ou dans de la documentation technique. Ne devrait jamais être utilisée sur de vrais réseaux. | 192.0.2.0/24 |
| 198.51.100.0/24 | ||||
| 203.0.113.0/24 | ||||
| ::/128 | Non spécifié | Unspecified | Utilisée comme adresse source par un hôte en cours d’acquisition de son adresse réseau. | 0.0.0.0 |
| ::/8 | Réservé | Reserved |
ex CIDR:
2001:db8:1f89::/48 prefix: 12*4=48 bits utilisés
128-48=80 => 2^80 ip disponibles => 20 caractères => 5 groupes de 4 => 2001:db8:1f89:ffff:ffff:ffff:ffff:ffff (dernière ipv6 disponibles)
Dans le cadre d’un “exponential backoff”, on peut introduit un “jitter” (une latence aléatoire) pour éviter les collisions.
Indicateurs significatifs permettant de mesurer les performances. Ils doivent être orientés expérience utilisateur (“time to process a request” mieux que “CPU loads”).
Schéma de haut niveau permettant de définir grossièrement la future architecture cloud. Cette proposition doit être flexible et évolutive afin de pouvoir suivre l’augmentation des besoins en termes de solution cloud pour couvrir le business à venir.
Stratégie de mise en cache la plus répandue consistant à mettre la donnée en cache UNIQUEMENT lorsque l’objet est réellement demandé par l’application.
Cycle d’effacement de la donnée par étapes (corbeille, données comme archivées, purge).
Le « lift and shift » (littéralement, soulever et déplacer) est une stratégie consistant à faire migrer une application ou une activité d’un environnement à un autre sans procéder à une refonte.
Méthode permettant de répartir la charge sur un ensemble de ressources dans le but d’avoir un traitement plus efficace
Méthode permettant de réduire les fluctuations de charge. Par exemple, une queue de message permet de niveler la charge (tampon) au niveau du consommateur. Ne pas confondre avec le load balancing.
Taille maximale du paquet transmis en une seule fois.
La version d’un produit qui permet d’obtenir un maximum de retours client avec un minimum d’effort
Automatiser le monitoring et la mise en place de KPI, notifier immédiatement en cas d’anomalie, ne faire intervenir un ingénieur que dans le cas où le SLO est menacée.
Permet à des ressources sans adresse IP externe d’avoir des connexions sortantes vers Internet.
Il a 2 types de services réseaux :
Prochain routeur où les paquets seront acheminés.
Stratégie d’entreprise focalisée sur la qualité et une meilleure organisation permettant de réduire les coûts (agilité, automatisation), les risques (monitoring) et d’améliorer l’expérience des utilisateurs des produits.
Charge courante pour exploiter un produit.
Prévenir la surcharge du système en mettant en place une stratégie d’équilibrage de charge.
Composant réutilisable contenant des services pré-packagés représentant des capacités et des fonctions métier spécifiques.

Un PBC peut contenir un ou plusieurs microservices isolés des autres microservices.

Le PBC et l’architecture composable permettent d’avoir les avantages de l’architecture microservices tout en diminuant la complexité en les regroupant par fonctionnalité métier.

La mise en miroir de paquets permet de capturer toutes les données relatives au trafic et aux paquets, y compris les payloads et les header. La capture peut être configurée pour le trafic sortant et entrant, uniquement pour le trafic entrant ou uniquement pour le trafic sortant.
Cette technique permet de surveiller et d’analyser l’état de la sécurité.
Voir IDS
Avoir une liste massive de login et utiliser un même mot de passe commun sur tous les comptes pour passer l’authentification
Produit permettant une gestion fine (contrôle, accès, monitoring) des ressources critiques en termes de sécurité
Pour un MIG régional, cette fonction (par défaut “active”) permet de redistribuer d’une façon équitable les VM dans toutes les zones de la région (équilibrage).
Durée maximale acceptable pendant laquelle on peut perdre des données en raison d’un incident majeur (quelques minutes pour des données utilisateurs fréquemment modifiées) (corrélation avec le temps de sauvegarde de données).
Durée maximale acceptable pendant laquelle votre application est HS (corrélation avec le SLO).
Abandon l’ancienne au profit d’une plateforme architecturée pour le cloud.
Faculté à un système à continuer de fonctionner malgré les incidents (panne, attaque …).
Composant permettant la communication entre deux réseaux distincts grâce à sa table de routage.
Mise à l’échelle vers l’extérieur ou vers l’intérieur, où vous ajoutez plus de bases de données ou divisez votre grande base de données en nœuds plus petits, en utilisant une approche de partitionnement des données appelée sharding, qui peut être gérée plus rapidement et plus facilement entre les serveurs.
En effectuant un scale-up ou un scale-down, où vous augmentez ou réduisez la puissance de calcul ou les bases de données selon les besoins, soit en changeant les niveaux de performances, soit en utilisant des pools de bases de données élastiques pour vous ajuster automatiquement aux demandes de votre charge de travail.
tags: [architecture,gcp] type: “post” date: “2024-05-06” ref: https://fr.wikipedia.org/wiki/Security_information_and_event_management description: systèmes de gestion des événements et des informations de sécurité
acronyms: SIEM
Domaine d’outils fournissant en temps réel des alertes de sécurité générées par les applications et le matériel réseau. ex: Chronicle pour GCP avec log router Sink ou Spunkle
Paradigme de cloud computing dans lequel le fournisseur de serveur gère dynamiquement les ressources allouées au service client. Le prix dépend des ressources effectivement consommées et non des capacités d’un serveur acheté à l’avance. Mais le terme ‘sans serveur’ ne signifie pas qu’il n’y a pas de serveurs impliqués. Cela signifie qu’ils sont gérés par les fournisseurs et non par les consommateurs.
C’est la disponibilité et la fiabilité requise par le client final ou l’utilisateur du service.
Utilisé pour calculer le SLO et définir le service “minimum” pour satisfaire le SLO.
C’est l’objectif que l’on voudrait atteindre pour un service, le SLO est un objectif interne et n’est pas partagé avec le client.
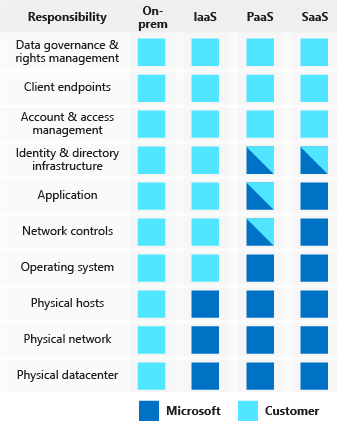
Les responsabilités sont partagées et permettent de définir les actions de chacun. Shared Fate définit la communication et la relation de collaboration. Ex : le cloud provider s’engage sur la transparence, l’accompagnement.
En hébergeant une solution sur le cloud, une responsabilité partagée en matière de sécurité est en vigueur. Le fournisseur doit gérer la sécurité de sa plateforme et le client est en charge de la sécurité de son produit déployé sur le cloud. (appliquer les bonnes pratiques du cloud provider, développement, sécurité… ) .
L’objectif est de créer le système logiciel le plus évolutif et fiable possible. Le SRE est “ce qui se passe quand un ingénieur logiciel est chargé de ce qu’on appelle des opérations”.
Décharge le cryptage SSL sur les connexions entrantes au serveur Web pour soulager celui-ci du traitement cryptographique (voir GLB SSL proxy).
Référence unique d’un produit utilisée en gestion de stock.
Le HTTP Strict-Transport-Security (HSTS) est une extension du protocole HTTP et permet d’informer le navigateur que ce site est accessible strictement en HTTPS et que toutes les demandes futures seront automatiquement redirigées vers le protocole HTTPS. Cela permet de garantir une connexion securitaire et de proteger contre les attaques de type man-in-the-middle.
Composant permettant la communication des ressources au sein d’un même réseau.
Test l’ensemble du code sur un environnement de test proche de la production.
le flux de données horizontal dit “est-ouest” concerne la communication sur le LAN ou d’un même centre donnée. le flux de données vertical dit “nord-sud” concerne la communication avec le monde extérieur. (LAN <-> internet)
Principe de rejeux de l’action en augmentant le temps entre chaque tentative afin de ne pas engorger le système.
Test d’une petite partie de code totalement indépendant.
Le client décide de partir (ex : concurrent moins cher) mais la donnée n’est pas accessible et ne pas être supprimée de la plateforme Cloud (utilisation de format propriétaire).
Le risque qu’un fournisseur de cloud fasse faillite et que les clients ne puissent pas récupérer les données.
Règles de sécurité pour protéger l’application (filtere d’IP, SQL injection, cookies introspection…).